leveldb 源码分析(1)varint
一、背景
level db底层对字符的存储是按varint进行编码的。varint是一个紧凑的编码方式。数字越大占用的字节数越大。存储的文本有并不总是大的数字,所以一定程度上,能够减少存储的空间。
二、编码方式
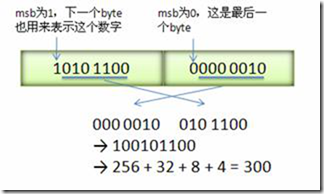
1. 首先编码后的数字,被放到一个字符数组里面。
2. 每个字符八位,最高有效位代表剩下7位的内容是在原来数字的某个位置。
3. 如果这位是1,则代表下一个字节的内容也是编码这个数字的。而且位置比当前还高。
4. 如果这位是0,则代表下面的字节不是编码这个数字的。也就可以解析结束了。
5. 通过上面的分析,我们可以得知。32位的int,最多要5个字节来编码存储。64位的int,最多要10个自己编码存储。解码的话只要一位位的去分析,知道遇到最高位是0 的字节就终止。
三、代码介绍
编码32位int:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | char* EncodeVarint32(char* dst, uint32_t v) { // Operate on characters as unsigneds unsigned char* ptr = reinterpret_cast<unsigned char*>(dst); static const int B = 128; if (v < (1<<7)) { *(ptr++) = v; } else if (v < (1<<14)) { *(ptr++) = v | B; *(ptr++) = v>>7; } else if (v < (1<<21)) { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = v>>14; } else if (v < (1<<28)) { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = (v>>14) | B; *(ptr++) = v>>21; } else { *(ptr++) = v | B; *(ptr++) = (v>>7) | B; *(ptr++) = (v>>14) | B; *(ptr++) = (v>>21) | B; *(ptr++) = v>>28; } return reinterpret_cast<char*>(ptr);} |
简直就是暴力。每次检查,从最低有效位开始存。最后把移动过的指针返回。
编码64位int:
1 2 3 4 5 6 7 8 9 10 | char* EncodeVarint64(char* dst, uint64_t v) { static const int B = 128; unsigned char* ptr = reinterpret_cast<unsigned char*>(dst); while (v >= B) { *(ptr++) = (v & (B-1)) | B; v >>= 7; } *(ptr++) = static_cast<unsigned char>(v); return reinterpret_cast<char*>(ptr);} |
简单明了。
解码32位int
1 2 3 4 5 6 7 8 9 10 11 | bool GetVarint32(Slice* input, uint32_t* value) { const char* p = input->data(); const char* limit = p + input->size(); const char* q = GetVarint32Ptr(p, limit, value); if (q == NULL) { return false; } else { *input = Slice(q, limit - q); return true; }} |
对input字符串里面最近的一个varint进行解码,然后放到value指向的内存位置。
奇怪的是这里面还调用了GetVarint32Ptr。然后把input的指针移动向下一个未解析的位置。
下面是这个的代码:
1 2 3 4 5 6 7 8 9 10 11 12 | inline const char* GetVarint32Ptr(const char* p, const char* limit, uint32_t* value) { if (p < limit) { uint32_t result = *(reinterpret_cast<const unsigned char*>(p)); if ((result & 128) == 0) { *value = result; return p + 1; } } return GetVarint32PtrFallback(p, limit, value);} |
如果是小数的话,直接返回放弃指针的下一个位置,如果是比较大的则调用GetVarint32PtrFallback进行解析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | const char* GetVarint32PtrFallback(const char* p, const char* limit, uint32_t* value) { uint32_t result = 0; for (uint32_t shift = 0; shift <= 28 && p < limit; shift += 7) { uint32_t byte = *(reinterpret_cast<const unsigned char*>(p)); p++; if (byte & 128) { // More bytes are present result |= ((byte & 127) << shift); } else { result |= (byte << shift); *value = result; return reinterpret_cast<const char*>(p); } } return NULL;} |
也是每一位检查有没有最高有效位1,有的话,解析出来放到目标value下。如果没有,就进行返回。通俗易懂。
编码64位就更简单了:
1 2 3 4 5 6 7 8 9 10 | char* EncodeVarint64(char* dst, uint64_t v) { static const int B = 128; unsigned char* ptr = reinterpret_cast<unsigned char*>(dst); while (v >= B) { *(ptr++) = (v & (B-1)) | B; v >>= 7; } *(ptr++) = static_cast<unsigned char>(v); return reinterpret_cast<char*>(ptr);} |
四、彩蛋
最近看头号玩家,居然用上了这个。好吧,本篇文章还没结束。
leveldb 其实是个单机存储引擎。对一个字符串的存储,其实不会像上面进行编码。会把字符串的上面进行varint编码放content里面,然后把实际内存追加到后面:
1 2 3 4 | void PutLengthPrefixedSlice(std::string* dst, const Slice& value) { PutVarint32(dst, value.size()); dst->append(value.data(), value.size());} |
这里的PutVarint32源码:
1 2 3 4 5 | void PutVarint32(std::string* dst, uint32_t v) { char buf[5]; char* ptr = EncodeVarint32(buf, v); dst->append(buf, ptr - buf);} |
看完是不是感觉很巧妙?
 评论 (0)
评论 (0)